サーバー機器にはデスクトップPCとは異なる信頼性が要求される。
デスクトップPCは個々の端末がダウンしても、困るのはそのPCを使用している人だけだ。
ダウンしても再起動すれば、だいたい元通りに使える。
しかし、サーバーがダウンした場合は社内システムでも数十人から数千人の利用者が、そのシステムを利用できなくなる。
公のインターネットに公開されるシステムの場合は、数万人から数千万人の人々がシステムを使用できなくなる。
重要なシステムの場合は、一部の人々の生死にも関わる。
もう一つ重要な点として、サーバー機がデータ更新中にダウンしてしまったときに、そのデータが失われたり、データの整合性が壊れたりして、その後にそのテータが使用できなくなる場合もある。
だから、サーバー機器にはデスクトップPCよりも高度な信頼性が要求される。
この記事では、広くIT系システム全般に要求される信頼性を向上させる技術や考え方と、そこで必要になる機器の種類を解説する。
「システムの稼働率を最大化する技術」と、「データとその整合性を守る技術」と関連IT機器の解説だ。
ネットワークやセキュリティに関する解説はしていない。
デスクトップPCとサーバー機は、どちらも同じAT互換機ではあるが、要求される信頼性のレベルは全く比較にならない。
サーバー機には非常に高い信頼性が要求される。
理想を言えば決してダウンしない事が望ましい。
しかし現実には、それはあり得ない。
少し前に起こった au や ドコモ の通信障害を見れば分かるように、システムというものはどんなに堅牢に高い信頼性を維持するように造っても、必ずある程度ダウンするものなのだ。
最近では Microsoft の Teams も一時的にダウンしたようだ。
楽天モバイルも2時間ほどダウンした。
他のIT大手のシステムやITサービスも時々ダウンしている。
情報システムの世界では何十年も前から、情報機器は必ず故障するもので、故障によってITシステムが使用できなくなるリスクと時間を最小限度に抑える技術がいくつも生み出されてきた。
誤解の無いように言っておくが「システムがダウンしない技術」というものは存在しない。
どれも「システムがダウンする確率を最小化する技術」だ。
仮に1%の確率でダウンする機器があれば、それを0.3%にするような技術だ。
完全にダウンしないことなどあり得ないからだ。
情報処理技術者試験などで出題される技術などから、その信頼性を高める技術の全体像を紹介する。
高い信頼性を要求されるサーバー機とその周辺にはこれらの技術が生かされる。
信頼性評価
まず、ITシステムはどのような尺度でその信頼性を評価しているのか解説する。
評価特性:RASIS
システムの性能とは別に「いかに正常に稼働するか」を基準にした評価基準をRASISと呼ぶ。
5つの評価特性の頭文字を並べてRASISと呼ぶ。
信頼性(Reliablity)
可用性(Avaliability)
保守性(Serviceability)
保全性(Integrity)
安全性(Security)
信頼性(Reliablity)
故障しないで稼働している時間の長さ。
故障する頻度が多いと、評価が下がる。
可用性(Avaliability)
必要なときに必要なだけシステムを使うことができるか。
故障で使う事ができない機会が多いと、評価が下がる。
保守性(Serviceability)
故障したときに、どれだけ早く復旧できるかを示す指標。
復旧に時間がかかると、評価が下がる。
保全性(Integrity)
システムのデーターベースに保存しているデータの一貫性が損なわれずに保全される性能の評価指標。
故障により一部のデータが失われると、評価が下がる。
安全性(Security)
情報の機密性を意味する。
データが外部に漏洩したり、故障により失われたりすると、評価が下がる。
評価指標
評価特性を具体的な数値で計測するための評価指標を紹介する。
MTBF:平均故障間隔
MTBFは Mean Time Between Failures (平均故障間隔)の略である。
前回システムが故障してから、次に故障するまでの時間の平均値。
つまり「故障しないで正常稼働している時間の長さ」の平均値である。
信頼性(Reliablity)の評価指標だ。
MTTR:平均修理時間
MTTRは Mean Time To Repair (平均修理時間)の略である。
システムが故障してから、復旧するまでの時間の平均値。
保守性(Serviceability)の評価指標だ。
稼働率
全時間の中で、システムが正常稼働している時間の割合。
稼働率 = 正常稼働している時間 ÷ 全時間
正常稼働している時間は MTBF であり、
故障している時間は MTTR なので、
全時間は (MTBF + MTTR) となる。
正常稼働している時間の割合が、稼働率なので数式は以下になる。
稼働率 = MTBF ÷ (MTBF + MTTR)
可用性(Avaliability)の評価指標だ。
例えば、24時間稼働するシステムの場合、年間10日間ダウンするとしたら、稼働率は97.2%となる。
1000時間稼働して故障し復旧に1時間かかれば、稼働率は99.9%である。
次に1200時間稼働して故障し復旧に2時間かかれば、両方の平均値なので稼働率は99.86%となる。
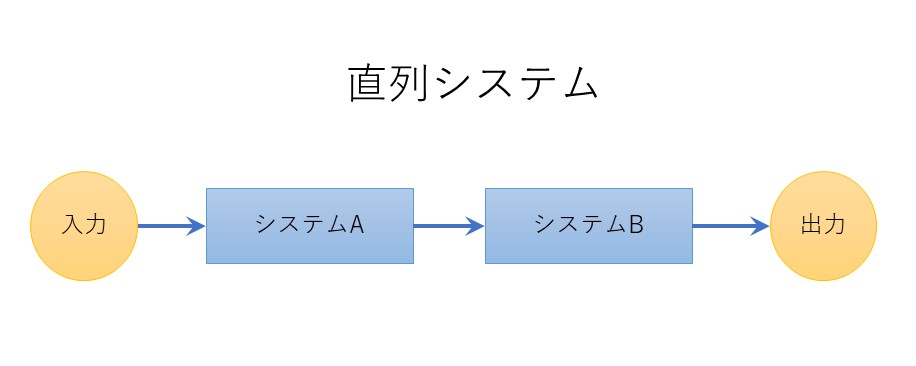
直列システムの稼働率

システムAとシステムBの二つのシステムがあり、両者が直列に繋がっているとする。
この場合、システムAとシステムBの両方が稼働していないとシステム全体が止まってしまう。
このような構成を「直列システム」と呼ぶ。
前工程と後工程の両方が動いていないと、機能しないシステムなどが直列システムである。
直列システムの稼働率は、全体を構成する個々システム稼働率の積である。
この場合は、システムAの稼働率とシステムBの稼働率の積が、全体の稼働率となる。
直列システムの稼働率 = システムAの稼働率 × システムBの稼働率
システムAの稼働率が 99% で、システムBの稼働率も 99% ならば、
全体の稼働率は 98.01% となる。
並列システムの稼働率

システムAとシステムBの二つのシステムがあり、両者が並列に繋がっているとする。
この場合、システムAとシステムBのどちらかが稼働していれば、全体が稼働することができる。
片方がダウンしたとき、性能は少し落ちるかも知れないが。
このような構成を「並列システム」と呼ぶ。
DNSサーバーやWindowsのアクティブディレクトリ・サーバーなどのように、プライマリーサーバーとセカンダリーサーバーがあるシステム構成が並列システムになる。
並列システムの稼働率は、100% から「全体の故障率」を引いた値になる。
故障率は稼働率の裏側なので、100% - 稼働率 = 故障率 となる。
全体の故障率は、システムAとシステムBが両方故障する確率なので、「システムAの故障率」と「システムBの故障率」の積が「全体の故障率」となる。
よって数式は、
並列システムの稼働率 = 100% - (100% - システムAの稼働率) × (100% - システムBの稼働率)
となる。
並列システムの稼働率 = 100% - (システムAの故障率) × (システムBの故障率)
と書いた方か分かりやすいと思う。
バスタブ曲線(故障率曲線)

x と y の二次元座標で、縦の y座標に「故障率」を取り、横の x座標にシステムの稼働時間を取る。
すると、システムの故障率は、システム運用初期には高く、その後は低く推移し、機械が老朽化したころに故障率が高くなる。
その故障率曲線は、浴槽の断面図のようにお椀型になることから「バスタブ曲線」と呼ばれる。
初期の故障率の高い期間を「初期故障期」、中間の故障率の低い期間を「偶発故障期」、老朽化によりまた故障率の高くなった期間を「摩耗故障期」と呼ぶ。
「偶発故障期」は、稼働している機器の定期点検や、古くなった部品を故障する前に交換するなどして、引き延ばす事ができる。
IT機器では無理だが、機械や設備によっては、補修を繰り返すことで、ほぼ永続的に「偶発故障期」を伸ばす事もできる。
IT機器でも、メンテナンスと修理で「摩耗故障期」の訪れるタイミングを遅らせることはできる。
また、補修を繰り返しても「摩耗故障期」になってしまったのなら、式年遷宮のように新しい機械に交換すべきである。
この概念も、システムの稼働率を高める大事な方法論である。
信頼性評価は「故障」を中心に考える
以上までの信頼性評価の方法を見ると、ほとんどが「故障」している時間や頻度を中心に考えていることが分かると思う。
「システムは必ず故障する」という前提で信頼性を高くする創意工夫が行われていることが分かると思う。
間違っても「絶対に故障しないシステム」などというあり得ない物など想定していない。
ITシステムも含めて全ての機器は、以上のような評価基準で故障率と稼働率を計測し、稼働率の最大化を目指しているものなのだ。
稼働率は決して 100% にはならない。故障率も絶対に 0% にはならない。
稼働率が 99% なら 99.5% にするにはどうすれば良いかを考えるものなのだ。
システム構成で信頼性を高める
単純に稼働率を高めたいのなら、システムの構成を並列システムにすれば、稼働率は上がる。
この並列システムの構成に工夫をして、稼働率を上げる手法は昔からある。それを紹介する。
デュプレックスシステム

システムのサーバー機を二つ以上用意し、一つをメインサーバーとして稼働し、もう一つを予備サーバーとして待機させておくシステム構成をデュプレックスシステムと呼ぶ。
メインサーバーがダウンしたら、待機していた予備サーバーに切り替えて、システムを稼働する。
メインサーバーは「現用系」、予備サーバーは「待機系」とも呼ぶ。
予備は一つとは限らない。
二台や三台の予備サーバーを設置していても良い。
予備サーバーの待機の仕方にも二種類ある。
メインサーバーと同様に、即時稼働できる状態で電源を投入してシステムを起動した状態で待機することを「ホットスタンバイ」、
メインサーバーが正常に稼働している間は、電源を落として待機している状態を「コールドスタンバイ」と呼ぶ。
予備機もダウンしたらシステム全体が停止する。
デュアルシステム

システムのサーバーを二つ用意して、どちらもメインサーバーとして二つ同時に稼働する方式をデュアルシステムと呼ぶ。
二つのシステムを同時に起動しているので、両者のデータに齟齬が生じることを防ぐ必要がある。
通常は、両者のデータを随時照合して同じ更新が行われるようにする。
定期的に二台のサーバーのデータをクロスチェックする方法もある。
二台のどちらかがダウンした場合は、片方のサーバーだけでシステムを稼働する。
二台ともダウンしたらシステム全体が停止する。
三台や四台のデュアルシステムにする事もできるが、台数が増えるとデータのクロスチェックや照合の負荷が増大し、システムのレスポンス性能が落ちる。
クラスタシステム

二台や三台ではなく、多数のサーバー機を用意して負荷分散装置などを用いて、多数のサーバーが一台のサーバーであるように振る舞うシステム構成をクラスタシステムと呼ぶ。
現代のクライアント・サーバー型のシステムでは、Web(AP:アプリケーション)サーバーとDBサーバーで分けて構成する。
Web(AP)サーバーを多数用意して負荷分散装置で端末からのアクセスを均等に多数のWeb(AP)サーバーへ分散させる。
DBサーバーは二台・三台・四台ぐらいで、互いのデータの同期(ミラーリング)を取りながらデュアルシステムのように構成する。
又は、DBサーバーのストレージだけ共有ディスク装置を用いて、複数のDBサーバーが同じ共有ディスク装置にアクセスすることで、データの整合性を保つ方法もある。
負荷を多数のサーバーに分散させて情報処理するので、パフォーマンスが良く、二台や三台・四台ぐらいサーバーが故障しても、システム全体にはほぼ影響が及ばす、システムを正常に稼働し続けることができる。
システムの稼働率は 99.99%という具合に非常に高くなる。
それでもシステムの稼働率は100%にはならないので注意。
DBサーバーはデータの整合性を保たなければならないので、数台ならともかく、Web(AP)サーバーのように何十台・何百台と多重化することはできない。
DBサーバーが全部ダウンすれば、システム全体がダウンする。
共有ディスク装置を使用する方式なら、共有ディスク装置が故障すればシステム全体がダウンする。
東証のクラスタシステムのダウンは共有ディスク装置の故障によるものだ。
グリッドコンピューティング
多数のコンピュータの普段使用されていない計算資源を借用して、分散情報処理を行うことにより、スーパーコンピュータのような高性能コンピュータを実現する方法が、グリッドコンピューティングである。
計算機資源を借用するコンピュータ全てに仮想コンピュータのソフトウェアを導入して、その仮想コンピュータ同士が互いに通信して、タスクを分業して処理する。
個々の仮想コンピュータがいくつかダウンしても、他の無数の仮想コンピュータが補完するので、全体がダウンする可能性は低い。
この方式は、科学技術系の計算には良いが、企業の業務システムや金融系の勘定システムなど、大量データの管理が必要なシステムの実装には向いていない。
構造的に重要なデータの保存にも向かない。
大学や研究機関の一部でしか使用されていない。
また、技術的にも規格の異なる多数のコンピュータ上で分散情報処理を行うのは難しいので、あまり発展しているとは言えない。
クラウドコンピュータ
クラスタシステムは特定のシステム専用に、多数のコンピュータを用意する。
グリッドコンピューティングは規格の異なるコンピュータ多数で分散情報処理を行う。データの保存には向かない。
この二つの欠点を解消したようなシステム構成がクラウドコンピュータだ。
クラウドコンピュータでは、単一規格のコンピュータを多数用意する。
そこで稼働するOSもホストOSは全て同じ単一のOSとなる。
これら単一規格多数のコンピュータ群に、分散情報処理技術で大規模なシステム構成を実現して稼働させる。
通常は仮想化技術を用いて、システムに必要なOSをゲストOSとして起動して、仮想的にいくつものクラスタシステムを作ってしてシステムを稼働する。
クラスタシステムがソフトウェアだけでいくつも用意できる上に、クラスタシステムを構成するサーバーの個数を増やしたり減らしたり自由に増減できる。
クラウドコンピュータの中では物理サーバー機の個数が数万・数十万というようにとてつもなく多いので、常にどこかのサーバー機が次々と故障する。
クラウドコンピュータの中ではDBサーバーのようにデータを保存する役割のサーバーのストレージデータは、少なくとも三つのサーバー上に複製されどれか一つのサーバー機が故障したら代わりのサーバー機が即時用意され、自動的に故障機と切り替えられて三重バックアップ体制で運用される。
少なくとも三重にバックアップしていればデータが失われる事は滅多に無い。
この辺の仕組みはそれぞれの事業者の提供するクラウドコンピュータの仕組みによって異なるが、基本的なバックアップの仕組みは大きく変わらないと思う。
もちろんWeb(AP)サーバーが故障しても代わりのサーバー機に切り替わる。
この仕組みだと絶対に故障して停止することは無いように見えるかも知れないが、クラウドコンピュータでも個々のユーザーは障害により一時的に使えなくなる事はある。
例えば、クライアント端末からクラウドへアクセスする入り口部分がダウンすることがある。
最近だと Azure AD が広い範囲で使えなくなったことがある。
2021年にAWSでもネットワーク機器の障害で、大規模障害が起こった事がある。
そもそもAWSもAzureも100%の信頼性など保証していない。
AWSの可用性は99.99%である。0.01%の確率で停止することになる。
0.01%と言えば、年間52.5時間ぐらいだ。
本当に年間52時間停止するということではなく、AWSは年間52時間ぐらい停止する事を前提に利用してくれと言っているのである。
100%の信頼性など保証していない。
他のクラウドコンピュータも同じようなものである。
システム構成による信頼性向上の手段
これまでのシステム構成の解説を見ればわかると思うが、システム構成による信頼性向上の手段は、一言で言えば「コンピュータを並列に複数繋いで、一部が故障しても全体がダウンしない方法」である。
サーバー機器を設置するときも、この方法論を中心に考える。
これに加えてセキュリティを考慮したハードウェア機器の設置をすることになる。
セキュリティはソフトウェアへの依存が多いが、ハードウェアの配置も無視できない。
サーバー機器は必ずいつか故障するので、いかに複数のサーバー機器を互いに補完させて、全体がダウンしないように工夫するかが重要なのだ。
それでも完全にダウンしないことはあり得ない。
他にサーバー機器の設置で重要なのは、停電した時に臨時の電源を供給する無停電電源装置(UPS)と、サーバー機の中のデータベース・サーバーのデータをバックアップする様々なバックアップ装置とバックアップメディアである。
バックアップ装置には外付けハードディスク・テープメディア・光学ディスクなどいくつか種類がある。
サーバー機器の設置は、紹介したシステム構成のどれかを導入し、加えて停電対策の無停電電源装置と、バックアップ機器を設置して、定期的にバックアップ機器を使用してバックアップ・メディアにデータベースの内容を保存する。
このような形でサーバー機器を導入することになる。
他にクライアントが社内ネットワークの中か、在宅勤務のように外部にクライアントが存在するかによってネットワーク機器の設置の仕方も変わってくる。
クライアント・サーバー構成
ソフトウェアの面から見ると、現代のITシステムはほぼ全てクライアント・サーバーと呼ばれるソフトウェア構成で作られたシステムである。
スマホアプリもWebアプリケーションもどちらもクライアント・サーバー構成のシステムだ。
クライアント・サーバーのクライアントとはユーザーが直接使用するPCで稼働するソフトウェアの事で、スマホやデスクトップPCのアプリを意味する。
Webアプリケーションの場合は、JavaScriptなどでダウンロードされてくるプログラムがクライアントに該当する。
サーバーとは、そのクライアント・ソフトウェアがネットワーク越しに通信するサーバー側のソフトウェアを意味する。
つまり、クライアント・サーバーとはソフトウェアの構成のことであり、ハードウェアのシステム構成と組み合わせて、全体の情報処理の効率を考える。
クライアント・サーバー・ソフトウェアでは、情報処理をクライアント側とサーバー側で分担して行う。
個々のユーザーが使うクライアント端末で処理できる情報処理は、いちいちサーバーと通信しないでクライアント側だけで処理してしまう。
結果としてサーバー側には、サーバーでしか処理できない仕事しか要求されず、サーバー機の負荷は必要最小限になる。
効率の良い情報処理を行うためのソフトウェア構成である。
もっとも単純なクライアント・サーバー構成は、通称「2層クライアント/サーバー」と呼ばれる以下の構成となる。
2層という言葉は2階層の略で、最近は略称の方を使うようだ。

クライアント・サーバーを構成するとき、データベースを使用する構成では、データベース・サーバーを独立させて3階層クライアント・サーバーにすることが、現在の主流構成となる。

3階層クライアント・サーバーでは、当初はAPサーバーがビジネスロジックを格納し、データーベース・サーバーがデータの管理を担当するという役割分担が行われていた。
現在は、DBMSのストアドプロシージャを中心としたプログラミング機能が高性能になり、データーベース・サーバーでもビジネスロジックを実装するようになったため、ビジネスロジックの役割分担の側面は失われている。
シンクライアント
シンクライアントとはその昔、汎用大型コンピュータを使用するとき使われていたシステム構成で、ユーザーが使用する端末は、ディスプレイとキーボードとマウスしか搭載しておらず、リモートでコンピュータセンターに設置している大型コンピュータに接続して操作していた。
この端末にはCPUなどコンピュータの機能は搭載されていない。
この仕組みをシンクライアントと呼んでいた。
近年、最新のシステム構成でもセキュリティやコストなどの都合によりこのシンクライアントを実現するVDI(Virtual Desktop Infrastructure)という技術が使用されるようになった。
日本語では仮想デスクトップと呼ぶ。
Windowsにもリモートデスクトップというアプリが標準搭載されているが、これも仮想デスクトップである。
リモートデスクトップを使用すると、ネットワークに繋がる自機とは異なる Windows10や Windows Server にリモートでログインして、ローカル機でログインしているかのように使用できる。
Windows Server ではシステム管理などに良く使用される。
サーバーの仮想化
現在は、Hyper-V や VM-Ware などでOSごと仮想化する技術があり、サーバー環境もこの仮想化によって運用していることが多い。
特にWebサーバーやAPサーバーを仮想化して、スケーラビリティを確保するケースが多い。
データーベース・サーバーを仮想化するケースは少数派ではあるが、皆無というわけでもない。
クラウドコンピュータではユーザーはほぼ全部仮想化されたOSを使用する。
RAID
RAID(Redundant Arrays of Inexpensive Disks)とは、レイドと読み、一言で言えば「ハードディスクの物理構成」の事である。
複数のハードディスクを一台の仮想的なハードディスクとして使用することができるようにする技術である。
現代のサーバー機にはほとんどRAIDが装備されている。
高価な物ならデスクトップPCにすら装備されているものもある。
ストレージの階層で装置を並列化して容量拡大と、データの保全性(Integrity)を高める技術である。
RAID構成 には、RAID0, RAID1, RAID0+1, RAID3, RAID4, RAID5, RAID6 の7つの構成の種類があり、目的に応じて選択する。
複数ハードディスクの構成の仕方は、
「データを複数ハードディスクに分割保存する」ストライピングと、
「同じデータを二つのハードディスクに二重保存する」ミラーリング、
そして「複数のハードディスクのパリィティを作成保存する」パリティディスクを組み合わせて構成する。
パリティとは日本語で偶奇性(ぐうきせい)と呼び、対象とする値を必ず偶数か奇数にする数学の概念だ。
情報技術ではパリティを用いてパリティチェック(偶奇検査)という手法でデータの誤りを正確に検出する。
元々は昔、精度の低かった記憶装置やデータ通信の世界で、機器のデータエラーを検出し、正しいデータを得る為の技術である。
パリティチェックの方法論は簡単で、データを二進数で扱い(元からデータは二進数)、ビット単位で二次元平面上にデータを並べる。

例えば40バイトの二進数データを、横並び8ビット単位で、縦に並べるとする。
横に8ビット、縦に5ビットの表ができる。
この表の右に1ビット、下にも1ビットのパリティビット領域を作成する。
右のパリティビット1ビットには、横に並んでいる8ビットの値との和が奇数になる値を、格納する。
下のパリティビット1ビットには、縦に並んでいる5ビットの値との和が奇数になる値を、格納する。
この状態で、横に8ビット、縦に5ビットのデータの一部が壊れて、全部0の値になったとする。
すると、全データの縦と横の偶数と奇数の検査をすると、壊れたデータは偶数になっている。
二進数なので、奇数であるべき値が偶数になっていれば、正しい値は逆の値である。
つまり、0なら1、1なら0が正しい。
これを横と縦の両方で検査しているのだから、正確にどこの値が間違っていて、正しい値は何なのかも分かる。
これがパリティチェック(偶奇検査)による誤り補正という技術である。
RAIDではこのパリティビットの値をパリティディスクに全て格納している。
全データのバイト単位でのパリティ値を、パリティディスクに格納しておく。
すると、二つのハードディスクのどちらかが故障しても、正常デスクとパリティディスクの値を照合すると、故障ディスクのデータを復元する事ができる。
復元したデータは、故障時の予備であるスペアディスクというハードディスクに復元して、故障ディスクの代わりに機能する。
故障ディスクは定期点検時にでも、交換すれば元の状態に戻る。
RAID構成の中の RAID, RAID, RAID, RAID は、このパリティディスクとスペアディスクを使用して、少ない台数のハードディスクで冗長性を実現している。
RAID はストライピングとミラーリングとパリティディスクとスペアディスクの組み合わせ方を、用途に応じて組み替えて、冗長性・大容量化・保全性を都合の良いように変更する、ハードディスクの構成方法である。
RAID0, RAID1, RAID0+1, RAID3, RAID4, RAID5, RAID6 の7つの構成は、ストライピングとミラーリングとパリティディスクの組み合わせパターンの種類を意味する。

RAID0 は、ストライピングだけで複数ハードディスクを構成したもの。
最も大容量な構成になる。速度も速い。
欠点として一台でも故障すると、そのデータは失われる。

RAID1 は、ミラーリングだけで複数ハードディスクを構成したもの。
最も記憶容量は小さくなる。データ量の2倍のハードディスク容量が必要ななる。
速度も遅い。
しかし、ミラーリングディスクの片方が故障しても、データは失われない上に、システムはそのまま継続して稼働できる。

RAID0+1 は、ストライピングとミラーリングを両方採用したもの。
複数のハードディスクをストライピング構成にして、データを分割保存した上で、これを全てミラーリング構成にして、データ全てを二重保存している構成だ。
正確にはこれをブロック単位に分けて構成する。
データ量の2倍のハードディスク容量が必要になる。
速度はミラーリングのRAID1と同様に遅い。

RAID3 は、複数ハードディスクにデータをバイト単位で順番に分割して配置する。
仮にハードディスクが4台有る場合、1バイト目はAドライブ、2バイト目はBドライブ、3バイト目はCドライブ、4バイト目はDドライブ、5バイト目はまたAドライブ、というように並べる。
そしてハードディスク4台のバイト単位パリティ値をパリティディスクへ格納する。
4台の内、一台が故障しても、パリティチェックで消失したデータを復元できる。
復元したデータはスペアディスクに復元して、スペアディスクが故障したディスクの代理を務める。
故障したディスクを点検時に交換すれば、正常な状態に戻る。
データは全て復元可能だが、ミラーリングのようにデータ容量の2倍ものハードディスク容量は必要ない。
全データのパリティを確保できるハードディスク容量があれば、完全な冗長性を確保できる。
書き込みの度にバイト単位でパリティを更新するので速度が遅い。

RAID4 は、RAID3の発展型で、パリティ更新の効率を良くするために、RAID3のバイト単位パリティを、もっと大きなブロック単位のパリティに拡大して、高速入出力を実現する。
大きなブロック単位で読み込むので、読み取り処理は効率が良い。
大きなブロック単位でパリティ検査と計算を行うので、ブロック単位での入出力なら効率は良いが、少しのバイトを更新しただけでもブロック単位でのパリティ検査と計算を行うので、パリティディスクの更新頻度が高く、同一ブロックで二回以上更新する場合、後の更新は待たされることになる。
小さなデータ更新を繰り返す処理には向かない。
パリティディスクの更新負荷が高く、ここが故障し易くなる。
この欠点のため、あまり使用されていない。

RAID5 は、RAID4 のパリティディスクの負荷を分散して軽くし、欠点を改善した方式だ。
RAID4 のように専用のパリティディスクは持たず、ブロック単位にパリティブロックを用意して、複数のハードディスクに分散してパリティブロックを配置する方式。
4台のハードディスクがあるとすると、ブロック1はAドライブ、ブロック2はBドライブ、ブロック3はCドライブに配置して、この3つのブロックのパリティブロックをDドライブに配置する。
同じ要領で、次の3つのブロックはAとBとDドライブに配置して、Cドライブにパリティブロックを配置する。
次は、AとCとDドライブに配置して、Bドライブにパリティブロックを配置。
次は、BとCとDドライブに配置して、Aドライブにパリティブロックを配置。
次は元に戻って、AとBとCドライブに配置して、Dドライブにパリティブロックを配置するというふうにパリティブロックの配置を4つのハードディスクに分散する。
これにより、一つのパリティディスクに更新負荷が集中するのを防ぐ。
それ以外の性能は、RAID4 と変わらない。
原理はRAID4 と同じなので。
二台同時に故障すると、復旧できなくなる。

RAID6 は、RAID5 の障害耐性を高めたもので、パリティブロックを二重に保持する。
二つのパリティブロックを異なるハードディスクへ保存するので、二台のディスクが故障しても復旧できる。
更新時に二つのパリティブロックを更新しなければならないので、更新速度が遅くなる。
障害耐性より更新速度を優先するなら、RAID5 の方が早くて良い。
情報処理技術者試験などでは、RAID0, RAID1, RAID3, RAID5 だけしか試験に出題されないらしい。
データのバックアップ
サーバー機のデータのバックアップについて解説する。
3層クライアント・サーバーのシステムの場合は、Web(AP)サーバーとDBサーバーが存在するが、通常バックアップが必要なのはDBサーバーだけである。
Web(AP)サーバーは、コンテナや仮想環境の実行イメージだけ用意しておけば、それを必要に応じてコピーして稼働させれば良いので、リアルタイムのデータを保存する必要は無い。
DBサーバーはRAIDなどにより、リアルタイムのデータを保存する必要がある。
故障した時は、早急に復旧しなければならない。
RAIDによるバックアップは全てハードディスクによるバックアップであり、万が一故障してもスペアディスクなどにより、継続稼働可能な高性能で高価なパックアップの機構である。
しかし、データのパックアップはRAIDのような高価なバックアップだけで良いわけではない。
例えば、それほど予算の取れないシステムの場合はRAID構成自体を採用できない場合もある。
故障時に必ずしも早期復旧できなくても良いシステムもある。
データサイズがそれほど多くなく、復旧に2日ぐらいかけても良いなら、RAIDを構成する必要は無い。
もっと安価なバックアップ手段がある。
また、大規模高価なシステムのデータであっても、RAIDは使用するとしても、別途安価で大容量のバックアップ装置に何世代ものデータをバックアップして置く必要がある場合もある。
つまり、RAIDとは異なる、即時復旧には向いていないが、大容量で安価なバックアップ装置への需要は大きい。
必ずと言って良いほど、安価なバックアップ装置は使用される。
サーバー機には必須と言って良い。
その大容量で安価なバックアップ装置を紹介する。
バックアップ装置の大きな分類
バックアップ装置を大きく分類すると、4種類に分かれる。
高速で高価な順に並べると以下の順番になる。
ハードディスク
光メディア
リムーバブルディスク
テープデバイス
どれも昔のパソコンの補助記憶装置として使用されてきたデバイスである。
現在、これらの補助記憶装置は比較的安価なサーバー機の外部のバックアップ装置として利用されている。
テープデバイスなどは相当古い方式だが、バックアップ装置としては今でも立派に現役である。
ハードディスク
RAIDもハードディスクによるバックアップ装置の一種だが、ここで取り上げるのは外付けハードディスクの事である。
RAIDを構成するほど高価なシステムではないが、高速のバックアップ装置が必要な場合は、外付けハードディスクにDBのデータを保存しておいて、物理的にサーバーのある場所とは異なる場所で保存するやり方もある。
バックアップ用ハードディスクにバックアップデータを保存して、それを高速通信回線で別の地方の支部に送り、その支部で外付けハードディスクに保存しておくなどの運用も考えられる。
比較的安価なやり方だ。
通信方式としてはNAS:ナス(Network Attached Storage)が多く使用される。
通常のLAN回線でサーバー機と接続できるハードディスクだ。
パスワードや個人情報など、機密性の高い少ない容量のデータを外付けハードディスクに保存し、金庫に補完しておくなどのやり方もある。
原始的なやり方ではあるが、クラウド事業者を信頼できない場合は、充分に実用的なやり方である。
高度なセキュリティ知識が無くても、機密情報を守り易いのが長所である。
ハードディスクなので、復旧も早い。
ランダムアクセスなので、特定の情報だけ臨時に取り出す場合など、素早くアクセスできる。
ただ、ハードディスクなので他のデバイスに比べて、それなりに高い。
光メディア
ハードディスクのようにランダムアクセス可能で読み取りも早くデータ復旧も迅速にできる。
光メディアは比較的記録媒体が安価な点がハードディスクに比べて勝っている。
しかし、書き込み速度はハードディスクのように速くないため、リアルタイムな更新はできない。
また、繰り返し更新できる回数にも制限がある。
光メディアの種類にもよるが、一度しか書き込めないものや、1000回まで書き込めるものもある。
記録媒体の寿命が9年から20年以上とかなり長く、長期間のデータ保存に向いている。
CD-R, CD-RW, DVD-R, DVD-RW, DVD+RW, DVD-RAM, BD-R, BD-RE など沢山の種類がある。
容量は CD-R, CD-RW などで 700 MB、
DVD-R, DVD-RW などで 4.7 GB、
BD-R, BD-RE などで 25 GBと50 GB、
BD-RE XL で100 GBである。
どちらかと言えばバックアップよりアーカイブに利用されることが多い。
リムーバブルディスク
RDX(Removable Disk Exchange system)と呼ばれるサーバー機やDB専用のバックアップ用ディスクだ。
ディスクを簡単に取り外し交換することができる。
中身はハードディスクなので、実質的には外付けハードディスクの一種になる。
バックアップ専用に作られているので、軽量かつ頑丈で、災害耐性にも優れている。
複数台のRDXカートリッジを同時に扱えるRDXドライブもあり、データバックアップに便利な構造になっている。
ハードディスクなので、何度でも繰り返し使用できる。
停止していれば、多少の振動にも耐えられるように作られている。
サーバー機のバックアップは通常、このRDXかテープデバイスを使用する。
テープデバイス
テープデバイスは、LTO(Linear Tape-Open)と呼ばれ、磁気テープを使用した記録媒体である。
今の若い人は知らないだろうが、むかし音楽用のカセットプレイヤーなどの記録媒体に使用されていた。
初代のソニーのウォークマンがカセットプレイヤーだった。
このカセットプレイヤーと同じ原理の記録媒体がLTOである。
呼び方としては、テープデバイス・テープストリーマー・テープストレージなどとも呼ばれる。
LTOはバックアップメディアとしては最も安価で大容量なメディアである。
カセットテープの形式になっているので、持ち運びにも便利である。
ひとつのカセットテープで10テラバイト単位の大容量メディアだ。
寿命も30年程度と非常に長い。保存状態が良ければ50年保つとも言われる。
繰り返し上書き保存することもできる。
欠点としてシーケンシャルアクセスしかできないので、特定データだけランダムアクセスで取り出すことはできない。
纏まったデータを一度にバックアップして長期保存することに向いている。
データを復旧するときも、全データを一括で復活する。
部分的に取り出すことはできない。
テープデバイスは非常に古い技術ではあるが、今でも主流のバックアップデバイスである。
バックアップの際は、直接システムのハードディスクからテープデバイスへ書き込む事はない。
通常はシステムディスクから、まとめて外付けハードディスクやリムーバブルディスクへバックアップしてから、そのデータをテープデバイスへバックアップする。
バックアップ・デバイス構成
一般的なバックアップデバイスの構成は、NASハードディスクかRDXリムーバブルディスクの「Disk」と、LTOテープデバイスの「Tape」の組み合わせで構成する。
サーバー機ハードディスクから直接バックアップする時は、Diskに対してバックアップが行われる。
そのあと、RDXリムーバブルディスクやLTOテープデバイスなどの安価だが速度の遅い記録メディアに保存する。
代表的な組み合わせは以下のようなものがある。
D2T(Disk to Tape)

サーバー機のハードディスクからLTOテープデバイスへ直接バックアップする構成。
システムが夜間に停止するタイプであれば、夜間にはDBの更新は終わっているので、システムのハードディスクから直接テープデバイスへ書き込みできる。
テープデバイスは読み書きが遅いので、データ復旧には時間が掛かる。
ミッションクリティカル(停止しない)タイプのシステムでは、この構成は使えない。
テープデバイスへ書き込んでいる最中にシステムDBの内容が書き換えられてしまうので、バックアップデータの整合性がとれない。
夜間停止する小規模なサーバー機のバックアップに使用することが多い。
D2D(Disk to Disk)

サーバー機のハードディスクのデータを、NASやRDXなどのハードディスク型バックアップメディアへ保存する構成。
システムがダウンした時、素早く復旧する必要がある場合に使用する。
Diskはランダムアクセスできるので、部分的に失われたデータだけ復旧することもできる。
D2Tに比べて高価。
D2D2T(Disk to Disk to Tape)

サーバー機のハードディスクを一度、NASやRDXなどのハードディスク型バックアップメディアへ保存した上で、そのバックアップデータを更にテープデバイスへ保存する構成。
確実なデータの保護と、長期間に亘って古いデータを保存する必要がある場合に適している。
一度、ハードディスクへバックアップしているので、システム復旧時のデータ復旧も素早くできる。
ミッションクリティカル(停止しない)タイプのシステムの場合、一度高速ハードディスクにバックアップしてからでなければ、テープデバイスへバックアップできないので、ミッションクリティカルなシステムの安価なテープバックアップを実現するなら必須の構成となる。
この構成が一番高価になる。
しかし、長期保存メディアにテープデバイスを使用するので、RDXだけで長期保存するよりは、安価になる可能性もある。運用の仕方による。
まとめ
サーバー導入に必要な機器
ネットワークやセキュリティに必要な機器を除くと、サーバー導入に必要な機器は以下のようになる。
サーバー機(サーバー専用PC)
絶対に必須なもの。
高い信頼性が必要ならシステム構成のデュプレックスやデュアルシステムなどの構成で、複数台のサーバー機が必要となる。
サーバーOS
絶対に必須なもの。
バックアップ装置
絶対に必須なもの。
可能ならD2D2T構成を導入すべきだ。
理想はRDXとLOTの導入。
バックアップカートリッジから機密情報が漏洩したりするので、カートリッジの管理も重要だ。
RAID構成
これは必須ではない。
必要なデータ容量が大きいとき、又は高いデータ保全性が必要なときに必要。
無停電電源装置
絶対に必須なもの。
停電でシステムをダウンさせない為、又は突然の停電時にサーバー機を安全にシャットダウンするために必要となる。
DBMS(データーベース管理システム)などは、安全に終了するのに時間がかかる。
どれも単純に電源を切るだけですむものではない。
その他
これに加えて、社内ネットワーク機器(ルーターやスイッチングハブなど)と無線LANアクセスポイントなどが必要になる。
無論、ファイヤーウォールなどセキュリティソフトや機器も重要だ。
サーバールーム
IT機器ではないが、サーバーを安全に運用する為に、サーバー機器を扱える権限を持った人間以外は、サーバー機器やバックアップカートリッジに触ることができないように、サーバー機器を専用ルームに隔離するという措置も必要だ。
オフィスに顧客など部外者が頻繁に出入りする環境なら、鍵付きサーバールームは必須だ。
信頼性の担い手
以上「サーバーに要求される信頼性」という視点で、信頼性の考え方とその尺度、稼働率を最大化し故障率を最小化する技術の数々、そこで必要になる機器の解説を行ってきた。
これらはIT系の技術者には基本的な知識となる。
(基本情報処理技術者試験の出題範囲だ)
おそらく一般ユーザーの信頼性に対する認識とはかなり剥離があると思う。
しかし、ユーザーが利用しているあらゆるシステムは(通信回線も含む)このように「機械は必ず故障する」という考え方で実用的な信頼性を確保している。
企業やその他の事業所などが、サーバーやクラウドを導入するときも、システム運用において「故障した時どのように運用するか」を初めから業務計画に入れておく必要がある。
確認したわけではないが、
自衛隊や警察などは「故障時だけ紙とペンを使って人力で運用する」
鉄道などは「故障したら業務を止めてしまう」
通信サービスなら「故障したら競合他社に任せてしまう」
という運用をしているようだ。
「できるだけ故障停止しないための技術」はこれで分かったと思うし、同時に「システムは必ず故障する」ことも分かったと思う。
システムの信頼性を最大化するのは、IT業者の任務だが、完全なシステムは存在しない以上、人間によるシステム運用は「故障した時のことも想定しておく」のは、ユーザー側の業務担当者と経営者(リーダー)の義務だ。
信頼性の担い手は、システム担当者だけではなく、ユーザー側も含まれることは認識しておくべきだ。
自分自身の安全の為に。

